
20倍杠杆 「C位观察」数据流动的艺术:构建AI时代的高速通信网络

前言:在上一期的C位观察中,我们分享了对于生成式AI带来的技术革新和产业落地的思考。在大家尽情期待、拥抱和体验生成式AI和大模型的同时,我们也清晰地看到,中美在AI领域的合作和竞争是挑战和机遇的并存。因此,我们需要直面如何理清国内的优劣势,把各个环节进行拆解并实现追赶。从AI三要素即数据、算法、算力分别来看,数据和应用场景是国内AI行业的优势,算法模型上的差距也在逐步缩小,但算力依然是目前公认的最需要迎头赶上的环节。
为了实现算力层面的提升和追赶,国内有大量的厂商和从业者在各个产业链环节努力。但面对中短期内架构、制程、产能、出口禁令等多方面的制约,我们认为从芯片层面实现单点的突破依旧是非常困难且不足的。然而,借助国内电力、基建的优势,通过多卡、多节点、多集群的方式,以绝对数量上的堆积来取得突破,将是一条可行的路径。其实,全球行业的发展也正遵循着这个趋势,AI算力集群正从千卡向万卡甚至十万卡的规模演进。这个突破方向的关键是如何搭建起庞大的集群,如何让千卡/万卡能拧成一股绳以发挥更好的能效,我们认为互联通信将在其中扮演至关重要角色。因此本文主要会就数据中心内的互联通信,尤其是节点/集群间的通信,与大家进行分享交流。
(一) 算力、存储、互联通信-构建AI算力集群“高速交通系统”三要素
自大模型时代开启以来,产业界沿着Scaling Law在持续不断推出更大参数的模型和更多模态的模型,由此带来的海量数据的收集、分析和应用,使全行业的算力需求以惊人的速度激增。据统计,大模型训练对于算力的需求约每三个月翻一倍。能否获得更多、更高效的算力,成为了各个“玩家”最核心的竞争力之一。在这波此起彼伏的囤卡、搭集群、建数据中心的“军备竞赛”中,在摩尔定律逼近极限、单靠制程和架构带来的单卡算力边际提升效率放缓的背景下,除了花费大量资金和资源获得计算卡、服务器绝对数量的囤积优势外,如何在实际场景下充分发挥这些AI芯片的性能、如何持续提升数据中心整体的数据计算和处理效率,是产业正在探索的另一种可能事半功倍的方向。
通俗来看,如果将一个AI智算中心类比为以数据为中心的大型的交通运输网络,那么构建和运行这个运输网络最核心的三个要素就是算力、存储和互联通信。在这个大型运输网络中,如果我们认为每一个计算集群就是一个综合交通枢纽,那么算力主要解决的是这个交通枢纽内单个站点的流量通行速度问题,存储主要解决的是单个站点的流量上限问题,互联通信主要解决的是枢纽内部站点和站点之间,以及枢纽和枢纽之间的运力问题。三者相辅相成、三管齐下来提升整个运输网络的运行速度和效率。

图1:算力、存储、互联通信,构建数据中心“高速交通系统”的三要素
如何系统性地拓展这个“高速交通系统”用以处理更大规模的工作任务?目前业界主要有两种方式:1)Scale-up(向上/垂直扩展):通过增加单个系统的资源(如芯片算力、内存或存储容量)来提升其性能,即让一个单一的系统变得更加强大; 2)Scale-out(横向/水平扩展):通过增加更多的相同或相似配置的系统来分散工作负载,即添加更多的独立系统来共同完成任务。
延续前述交通枢纽的类比,Scale-up是针对单一枢纽的扩容,用更大和更多的站点来提升内部承载和通行能力,比如英伟达通过集成36颗GB200x芯片推出的DGX GB200系统。而Sclae-out则是建立和接入更多的枢纽来扩大整体的运输网络,例举英伟达DGX SuperPOD,可以集成至少8个甚至更多DGX GB200系统,并通过不断的拓展来实现数万颗GB200芯片的聚集。

图2:Scale-up vs Scale-out
从图2中,我们可以清楚地看到,算力和存储主要聚焦的还是Scale-up下单个枢纽内站点的规模和吞吐能力,大量的优化提升其实是来自于基础设施硬件的性能和软硬件的协同,对此业界通过架构、制程、介质、软件生态等多个方面已经做出了大量的努力,国内外也已涌现出一批优质的企业。
但解决Scale-up后枢纽内越来越多站点的接入和站点间运力问题,以及Scale-out后越来越多枢纽的连接和运输问题,则需要构建更好的运输能力,即互联通信的能力。与此同时,我们也观察到数据中心整体规模和实际性能&效率提升的天花板,更多地从以往算力的约束转变为互联通信的约束。换而言之,我们认为未来集群效率的提升重点会从计算转变为网络。因此,本文会将笔墨重点放在构建高速通道、支持和提升点到点之间运力能力的互联通信领域。

图3:I/O带宽与算力之间的差距逐渐扩大

图4:AI算力基础设施需要更好的互联通信能力,突破计算效率和规模瓶颈
(二) 互联通信-AI计算集群的快速通道系统,解决枢纽内和枢纽间的运输效率
AI计算集群的互联通信能力系统性的构建,主要来自三个方面,由内到外可以分为1)Die-to-Die(裸片间)互连:发生在芯片封装内,实现芯片内部不同功能模块间的数据交换;2)Chip-to-Chip(片间)互联:实现服务器内部,主板上不同芯片间(如 CPU-GPU,GPU-GPU)的数据通信;3)Board-to-Board(机间)互联:在服务器外部的通信,实现服务器-交换机、交换机-交换机之间的数据传输,并层层叠加形成数据中心集群的组网架构。

图5:数据中心各层级互联通信示意
为何英伟达在计算领域能如此强势?除了耳熟能详的芯片架构和CUDA软件生态外带来的单芯片的性能优势外,其在互联通信领域的多年布局,打出的一套面向Scale-up(NV Link、NV Switch)和面向Scale-out (InfiniBand) 的组合拳,使得其在节点和集群层面的性能和效率遥遥领先。

图6:英伟达DGX H100 SuperPod内部网络架构
从技术发展路线来看,Die-to-Die通信能力的提升目前主要依赖于2.5D/3D的先进封装和更加统一规范的高速Serdes等,Chip-to-Chip互联主要依靠更高速的PCIE、CXL协议以及英伟达独有的NVLink技术等,但这两条路线主要解决的还是芯片和服务器内部的通信效率,即我们前文提到的如何解决Scale-up的问题,这部分内容我们会在未来的系列文章中做更多的探讨。但我们认为, Scale-up因为受到物理空间、布线、工程实现等制约,整体可拓展的潜力和规模有限,而Scale-out作为Scale-up的进一步延续,会更具规模性和拓展潜力。
在大模型时代,过往传统AI单卡、单服务器或者单机柜即可解决的计算任务,已指数级地提升到需要千卡、万卡甚至是十万卡的分布式集群来支持。因此,如何提升服务器外部Board-to-Board、节点间/集群间的互联通信能力,解决前面说的更为关键的Scale-out带来的通信挑战,来构建整个数据中心的“高速运输网络”,变得越来越重要。那么如何实现大规模的Scale-up?大模型时代需要什么样的数据中心网络?需要什么样的软硬件和技术支持?我们可以继续往下一探究竟。
(三) 聚焦枢纽间的通行运输效率,解决Scale-up的问题,大模型时代需要什么样的数据中心网络?
大模型数据训练量大,且主要通过数据并行和模型并行进行训练,因此需要采取分布式集群、多节点的训练方式,且节点之间需要进行中间计算结果的实时高频通信,由此带来数据通信的两个新的大趋势:1)网络流量大幅增长;2)由传统数据中心的南北向流量为主转为AI数据中心的东西向流量为主。

图7:全球网络流量保持高速增长

图8:南北向流量往东西向流量转变
为了提高AI芯片有效计算时间占比、避免网络延迟和带宽限制拖累AI训练效率,对新型的AI数据中心通信网络提出超大规模组网、超高带宽、超低时延及抖动、超高稳定性和网络自动化部署等大量新的需求,并促使网络架构更新升级,从典型网络架构(树型)转向多核心、少收敛形态(胖树型、脊叶型)。
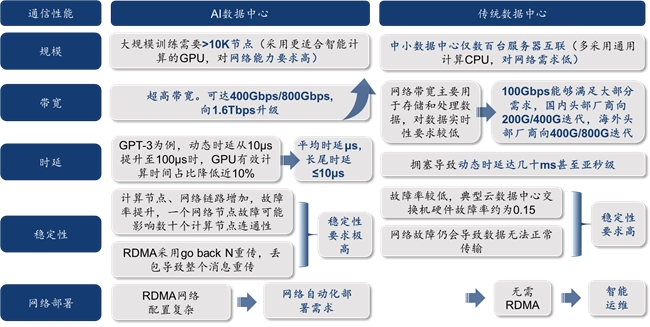
图9:AI数据中心相较传统数据中心,对通信性能和效率要求大幅提升

图10:左侧为传统数据中心网络三层树架构,右侧为AI数据中心三层脊叶架构
针对AI数据中心的低延迟、大吞吐、高并发等特点,传统的TCP/IP网络架构已无法满足应用的需求。因为传统的TCP/IP网络通信使用内核来发送消息,需要通过CPU来进行数据传输。这种通信模式具有较高的数据移动和数据复制开销,使得CPU需要负责大量的协议开销处理,从而导致更高的 CPU 负载和高流量,减慢其他任务的速度。面对这个问题,RDMA(Remote Direct Memory Access,远程直接内存访问)的横空出世,为节省数据传输步骤,提升通信效率带来了实际意义。与传统的IP通信不同,RDMA绕过了通信过程中的内核干预,允许网卡绕开CPU,主机可以直接访问另一个主机的内存,大大减少了CPU开销,将宝贵的CPU资源用于高价值的计算与逻辑控制上,从而提升了整体网络吞吐量和性能。
目前主流RDMA方案包括三种,层次结构和网络硬件设备各不相同:
· IB(InfiniBand):是专为RDMA设计的网络,最早由IBTA(InfiniBand Trade Association)在2000年左右推出。在设计之初即保证可靠传输,在RDMA方案中性能最优,硬件上需要使用InfiniBand专用的网卡和交换机。市场格局从起初的百花齐放,到现今英伟达/Mellanox的一枝独秀,生态较为封闭。
· RoCE(RDMA over Converged Ethernet):RoCE通过以太网实现RDMA功能,可以绕过TCP/IP并使用硬件卸载,从而降低CPU利用率,提升传输速度和功率,并降低成本。2010年起,IBTA发布第一个能够融合于以太网运行的RDMA-RoCEv1,基于以太网链路层实现RDMA协议,但在网络层仍基于InfiniBand协议。2014年发布RoCEv2,将 RoCEv1的 InfiniBand网络层替换为UDP/IP协议 仅在传输层使用 InfiniBand传输层协议。RoCEv2使用支持RDMA流控技术的以太网交换机和支持 RoCE的网卡。RoCE基于以太网,因此生态开放,“玩家”众多。
· iWARP(Internet Wide Area RDMA Protocol):基于TCP使用RDMA技术,但相比RoCE,大型组网时TCP连接仍会占用大量内存资源,数据传输效率仍较低,性能差于InfiniBand和RoCE。iWARP使用普通的以太网交换机,但需要支持iWARP的网卡。目前较少被使用。
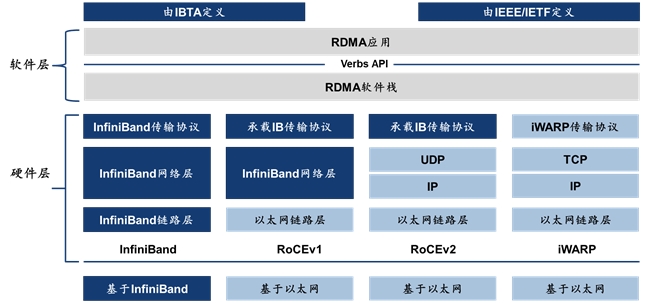
图11:IB、RoCEv1、RoCEv2、iWARP架构对比
(四) IB vs RoCE,选择高速铁路还是高速公路?
从技术和性能角度出发,目前构建数据中心内这个数据“运输高速系统”的最主流的两大路线,就是以英伟达/Mellanox一枝独秀、另辟蹊径的IB,以及其他厂商组成的“反抗军”、基于传统以太网改造升级的RoCE。
更为通俗的解释来看,如果把传统的通信网络比作是国道,那么IB就类似于一条另外新建的专有高速铁路,运输速度更快,效率更高,但只能跑基于轨道的高铁;而RoCE就类似于基于现有的国道升级改造成高速公路,帮助之前跑在国道上的各类车型以更快的速度和效率通行。因此,IB就是一位“专精单项的高手”,而RoCE则是一位“全能选手”。下面我们就通过一张图表,来看看它们在性能、部署复杂性、生态、成本等方面的较量:


通过表格直观的对比,我们不难看出IB在传输性能、集群规模、运维等方面具备一定优势。因此,在短期内部分厂商受限于军备竞赛下的算力资源紧张,或是选择借助IB的特点来快速搭建出集群用于模型训练,或是因自身组网能力不足直接选择英伟达成套的方案,IB在高性能计算领域暂时占据了更大的市场。但从中长期来看,由于RoCEv2基于以太网这个更加庞大、开放的生态和更好的跨平台支持,且具有更低的硬件成本和更广泛的供应商选择,随着其性能逐步接近IB,将会凭借其更好的经济性和兼容性,获得更加广泛的市场。
当然,IB和RoCE都在不断演进以应对未来的挑战,包括如何持续提高可用性、如何支持更大规模的集群等。IB的未来版本将继续提升带宽和降低延迟,以保持其在高性能计算中的领先地位;而RoCE则可能通过改进流控机制和拥塞管理,提高其在大规模网络中的表现。此外,2023年7月硬件设备厂商博通、AMD、思科、英特尔、Arista和云厂商 Meta、微软等共同创立了UEC(Ultra Ethernet Consortium,超以太网联盟),致力在物理层、链路层、传输层和软件方面开发新的开放式“Ultra Ethernet”解决方案,旨在推进高性能以太网的发展,以应对增长的智能计算通信需求。UEC联盟目前已有约70家成员公司,国内的华为、新华三、星融元、阿里、腾讯、百度和字节等厂商亦是联盟里的核心成员。

图12:UEC联盟成员示例
与此同时,我们正惊喜地看到以太网追赶IB的脚步正在不断加快。从技术路线来看,以太网已经紧追IB推出了800G的带宽产品,并有了1,600G的规划,且在时间线上并不落后。从下游客户来看,近期无论是Meta用于训练Llama的万卡集群,还是马斯克希望打造的十万卡集群,都优先采用了以太网的方案。从竞争对手来看,英伟达作为IB的领导者,也同步推出了全新的Spectrum-X以太网网络解决方案,并在近日加入了UEC联盟,业界认为这是英伟达多年“孤军奋战”后的第一次“顺势而为”。

图13:IB和以太网带宽路线图
·通过独立站打造 ChicMe 独有的品牌形象
(五) 在RoCE这条高速公路上,交换机、网卡和交换芯片是我们认为国内产业发展的核心基建
交换机、交换芯片和网卡是构建以太网基础设施最核心的部件。其中,交换机是现代网络&数据中心基础设施的核心组件,集成了各个核心硬件和软件操作系统,负责数据在网络中的传输和路由,全球主要供应商包括思科、Arista、华为等。交换芯片作为交换机里最核心的部件,决定了交换机的端口速率和吞吐量,技术门槛高,全球核心厂商包括英特尔、博通、Marvell等。网卡通过其物理接口与交换机相连,实现计算机与网络物理层的连接,决定了数据的传输和卸载速度,全球核心供应商主要集中在Intel、英伟达和博通等。
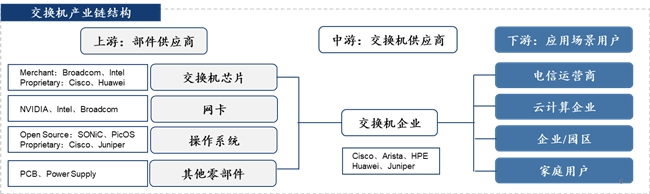
图14:交换机产业链
在交换机整机和操作系统层面,国内已经有一批具备全球竞争力的厂商,这其中既包括传统通信大厂华为、新华三等,也包括走白盒路线的锐捷、星融元等,它们纷纷推出了目前业界最高带宽的、基于800G端口的51.2T自研交换机,在产品和解决方案能力上并不落后于海外。但在核心交换机芯片和网卡领域,国内尚有较大差距,海外厂商占据了绝大部分的市场份额。在交换芯片层面,海外大厂博通、Marvell等已开始批量出货51.2T的交换芯片,实现了成熟的商业化,而国内的主流交换芯片还是以2.4T/3.2T为主,性能较弱无法满足大型互联网、数据中心的需求。在网卡层面,海外大厂供应给数据中心的网卡主流传输速度已经达到200G/400G bps的水平,并已经开始引入800G bps的网卡,但国内目前RDMA网卡的最高性能仍处于100G bps的水平。
整体来看,虽然国内在交换芯片、网卡等层面尚有差距,但在基于以太网的集群集成、核心交换机整机、光模块等领域均已有大量的突破。我们认为当前国内RoCE的产业阶段,或许与当年的新能源汽车类似,首先在整体(整车/交换机整机)和某个核心零部件(锂电池/光模块)开始突破,再基于此带动整个产业链的全面突破。
从行业发展来看,目前很多厂商仍旧坚持着过去传统的封闭软硬件系统和黑盒方案,从硬件的芯片、网卡、交换机整机,到软件操作系统一起打包出售和交付。但我们认为开放式的架构、开源的软硬件生态才是数据中心互联通信未来的方向,例如白盒&软硬件解耦的交换机产品、基于开源比如SONiC(Software for Open Networking in the Cloud)的云原生&容器化的通用网络操作系统、基于RoCE的商用网卡和交换芯片等。我们同样坚信,只有坚持开放、开源,打造泛在的生态联盟,国内才有可能在这一领域实现全面的突破。
(六) 结束语
本期主要围绕数据中心内,特别是集群间Scale-out的互联通信做了简单的概述,我们看好国内基于以太网的互联通信生态的发展,该技术路线也是国内公司未来在面对英伟达最有希望实现追赶的方向之一。虽然国内目前在交换芯片、网卡等硬件层面仍有差距,但已经有一批互联通信领域的创业企业开始崭露头角,可以预见本土行业将会迎来一波新的发展机遇,尤其是基于开放、开源生态的商用产品和软硬件解决方案厂商。
未来我们会围绕互联通信这一主题,在Die-to-Die互连、片间互联、板间互联等多个方向做更多的分享和交流。CMC资本将持续聚焦数据中心领域的核心技术和产业发展趋势,依托基金团队丰富的产业背景和深刻洞察,并结合AI算法厂商、芯片设计公司、晶圆厂、整机厂商等一线产业资源以及政府资源,在AI和算力基础设施领域进行全面布局,助力加速国产化的全面突破。
参考资料:
中金公司研究部:“AI浪潮之巅系列InfiniBand VS以太网,智算中心网络 需求迎升级”
中金公司研究部:“通信技术10年展望系列 224G PHY已启航,数据中心有线通信迈向新征程”